

Today, ST is officially becoming a member of MLCommons™, the consortium responsible for benchmarks quantifying machine learning performance in mobile platforms, data centers, and embedded systems, among others. The initiative enables engineers and decision-makers to grasp where the industry is heading and what they can accomplish. It also helps clarify what is feasible under a system’s constraints. Low-power embedded systems run the MLPerf™ Tiny benchmark and the test measures inference time and power consumption. ST devices have appeared in the closed division category of the benchmark since its inception. With our MLCommons membership, we can further assist partners in leveraging machine learning at the edge through objective and reproducible tests.
Check out ST’s GitHub and download the instructions and source code to run MLPerf Tiny on an STM32 microcontroller.
Why did ST join MLCommons?
The challenges of creating Tiny ML applications

The increasing ubiquity of machine learning at the edge, or Tiny ML, is ushering in the “Next Automation Age”. However, it has unique challenges that can leave many engineering teams perplexed. Developers wonder what kind of inference operations they can run on a microcontroller or the impact of an application on energy-constrained systems. Unfortunately, testing those limits is complex and costly. Finding a clean dataset is daunting. Teams must then create a neural network that can run on their hardware and undergo comprehensive tests. Put simply, it takes a lot more work than a simple programming loop writing values in a file.
ST’s initiative to make MLPerf Tiny accessible to all
ST brings a simple solution to this complex challenge by contributing to MLCommons and offering instructions and source code on GitHub so developers can run MLPerf Tiny on our platform. There’s even a Wiki with a simple step-by-step guide to get performance and power consumption metrics without having to implement what are traditionally complex processes. It’s about making it easy to compare ecosystems and empowering engineers to run the tests themselves. One can use the pre-trained quantized models from MLCommon or another supported model. The ST initiative thus highlights the importance of educating the community on what machine learning at the edge can do and the importance of the ecosystem, rather than just one component.
Measurements to quantify what STM32 and X-CUBE-AI bring to machine Learning at the edge

The ST results published on MLCommons’ page show an STM32L4, an STM32U5, and an STM32H7, all running X-CUBE-AI v7.3, the latest version of the software at the time. Previous submissions showed that when comparing an STM32U5 against another competing microcontroller relying on an Arm® Cortex®-M33, the ST ecosystem was 56% faster on inference while needing 74% less energy. When drilling into the data, we noticed that the STM32U5 runs at 160 MHz, compared to 200 MHz for the competing MCU. The lower frequency and the switched-mode power supply (SMPS) in the STM32 device explain, in part, the lower power consumption.
The other reason behind the numbers is the efficiency of X-CUBE-AI. The expansion package generates an STM32-optimized library from pre-trained neural networks. ST’s software improves performances by leveraging the STM32 architecture and accelerating inferences thanks to code optimizations and the ability to merge particular neural network layers. Some of these improvements are evident in MLPerf Tiny, such as the gains in inference times. However, the MLCommons benchmark doesn’t currently measure the size of the machine learning application in RAM. Yet, the memory footprint remains an important factor for engineers looking to reduce their bill of materials (BOM). Hence, we ran tests to compare memory usage after using X-CUBE-AI and TensorFlow Lite for Microcontrollers (TFLM).
Tensor Flow Lite for Microcontrollers vs. X-CUBE-AI
To offer a more comprehensive view of the performance gains and memory usage between STM32Cube.AI and TFLM, we performed two benchmarks. The first one revolves around image classification, and the second measures performances in visual wake word applications. All tests ran on the STM32H7A3 found on the NUCLEO-H7A3ZI-Q and all benchmarks performed in X-CUBE-AI 7.3 used the balanced setting, which finds the best compromise between the RAM size and inference times. For more information on the new optimization settings available in X-CUBE-AI 7.3, please check out our blog post.
Image classification: TFLM vs. X-CUBE-AI – Inference Time
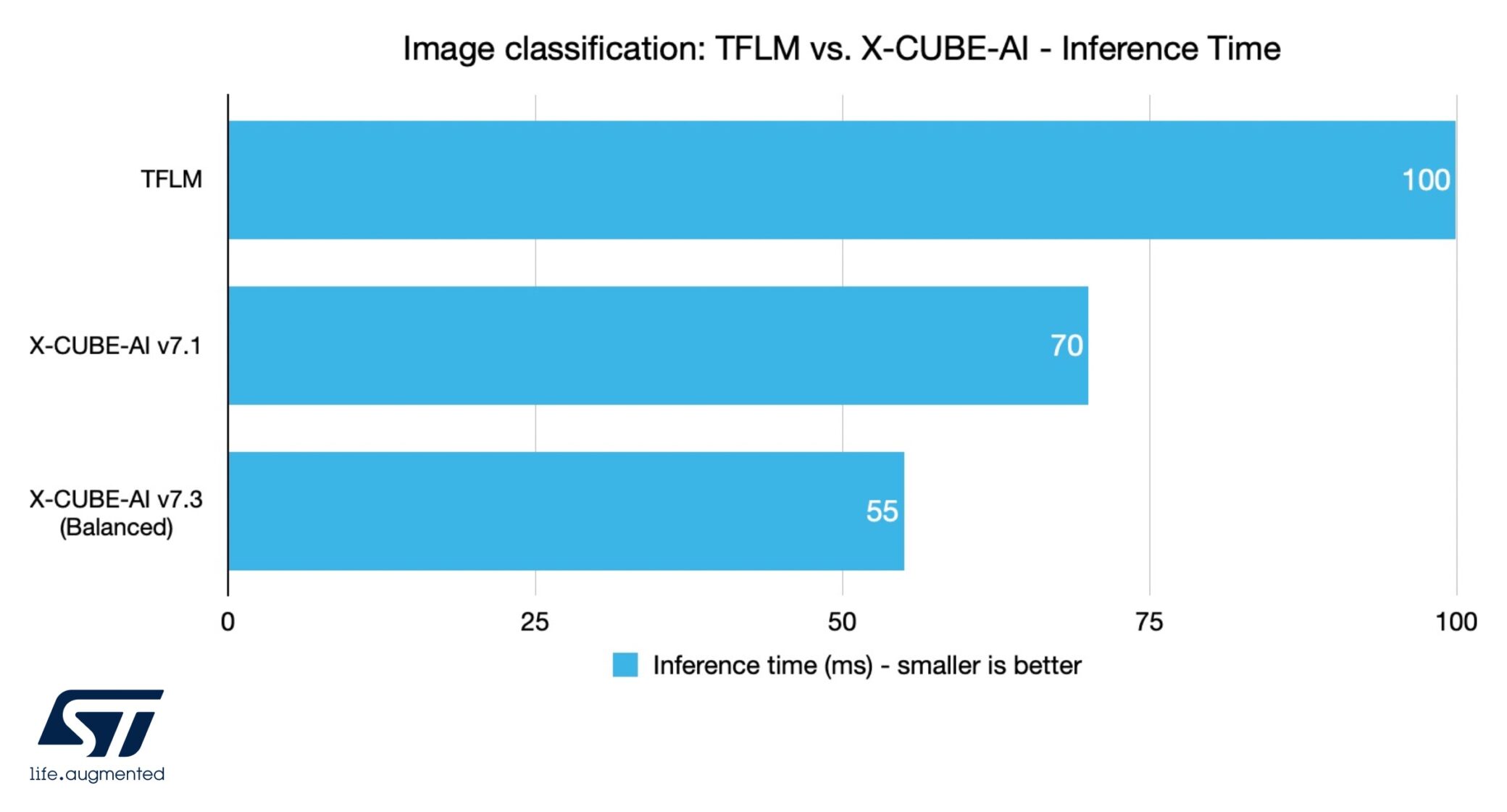
In the first test, the application produced by X-CUBE-AI v7.1 has inference times 43% faster than when using TFLM, while X-CUBE-AI v7.3 is 82% faster. The benchmark not only shows the benefits of our solution but the improvements from the latest release. Indeed, besides handling extended layers, STM32Cube.AI v7.3 provides more than 30% performance improvements thanks to various optimizations. The new version also supports deeply quantized neural networks, which thrive on resource-constrained microcontrollers.
Image classification: TFLM vs. X-CUBE-AI – Memory footprint
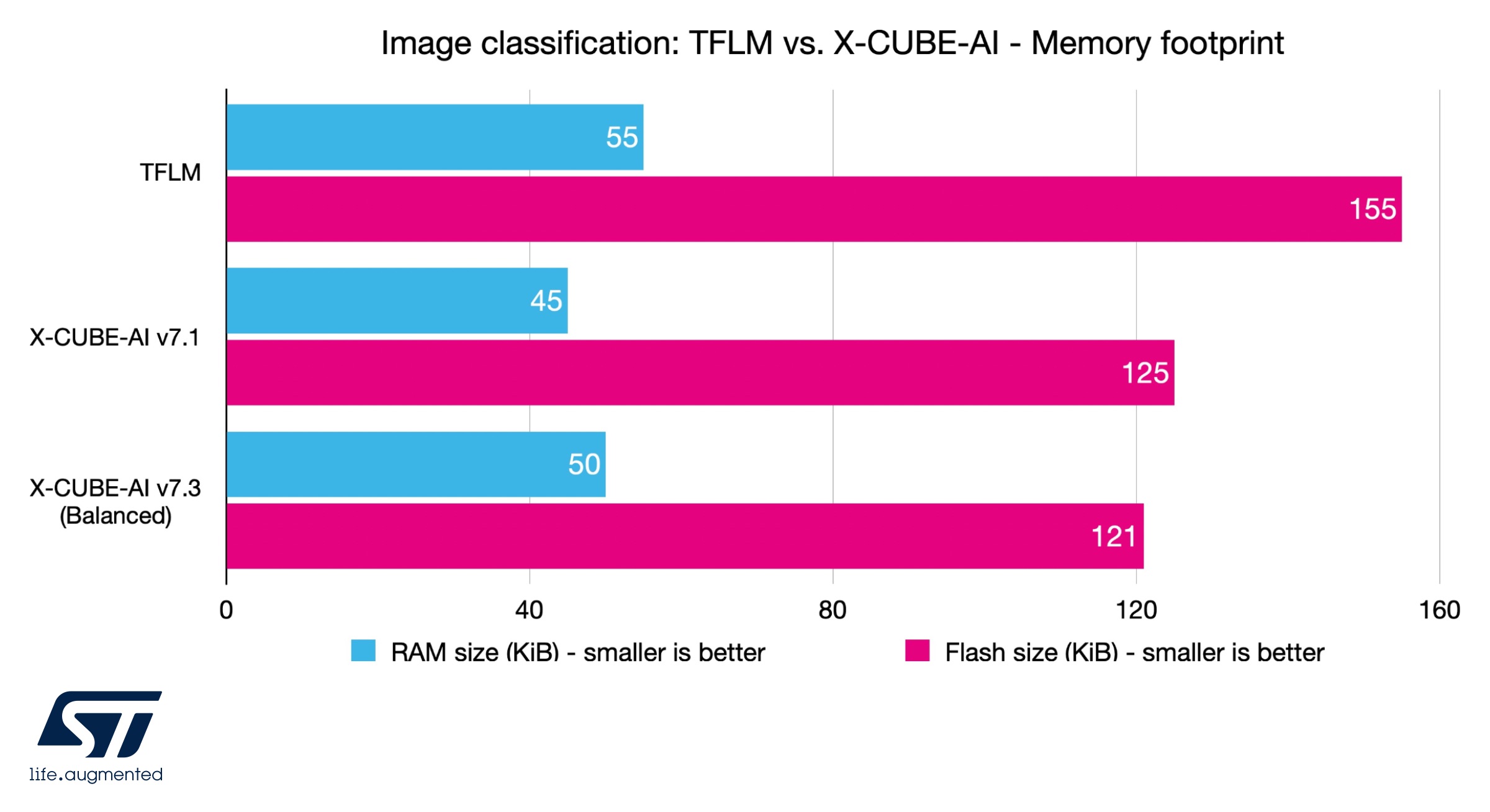
The memory footprint benchmark is interesting because it shows that despite offering significantly worse inference time than X-CUBE-AI v7.1, TFLM needs 22% more RAM and 24% more flash. The gap shrinks when comparing TFLM to X-CUBE-AI v7.3 because the latter’s support for extended layers necessarily demands more memory. However, the performance-per-memory footprint ratio still highly favors X-CUBE-AI v.7.3 since developers can achieve save 10% more RAM and 24% more flash.
Visual wake word: TFLM vs. X-CUBE-AI – Inference Time
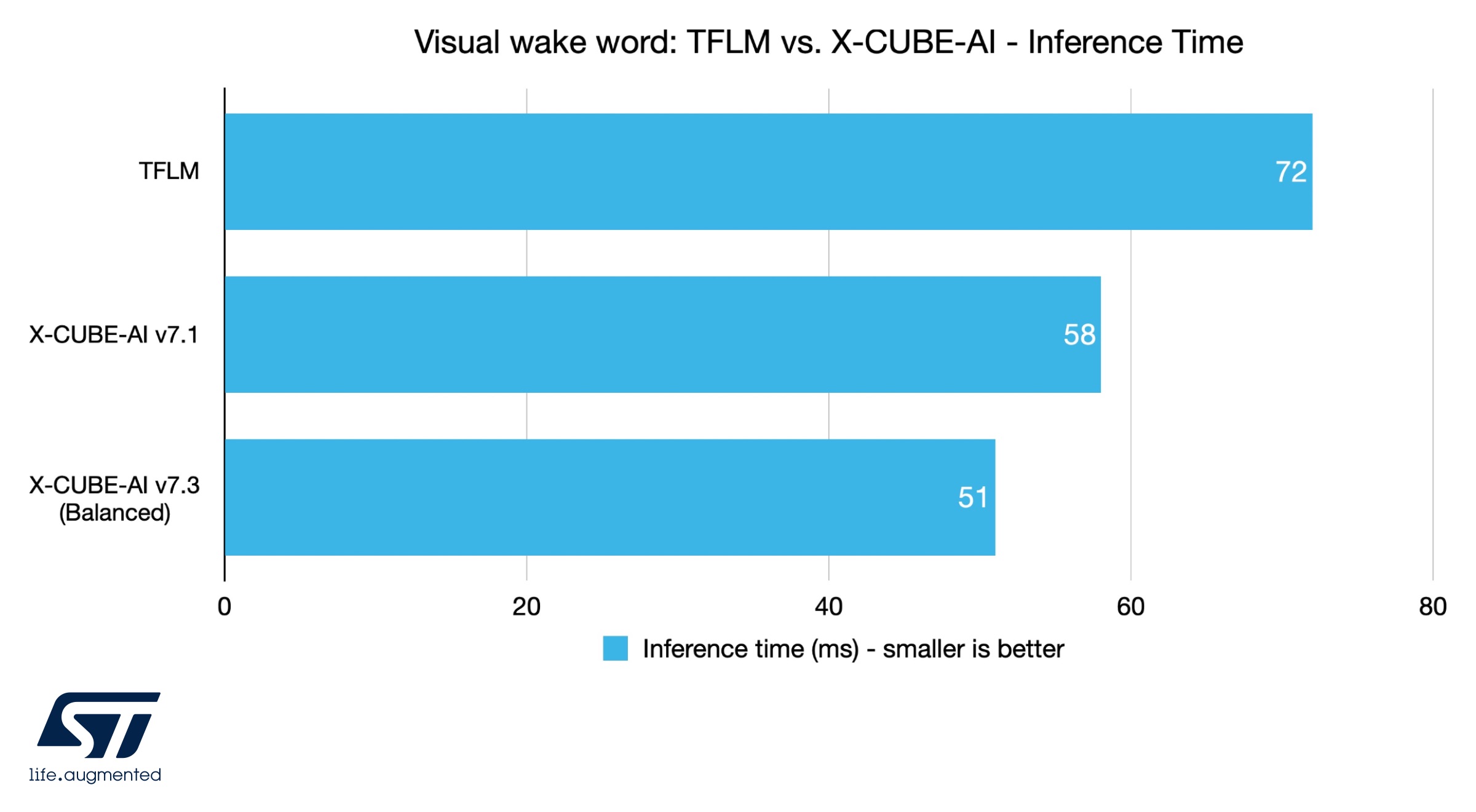
The visual wake word application is interesting because it is more sensitive to memory optimizations. Indeed, looking at the inference times, both versions of X-CUBE-AI bring significant improvements, with a gain of 24% for the earlier version and 41% for the latest release compared to Tensor Flow Lite for Microcontrollers. However, the next benchmark shows drastic improvements in memory footprints.
Visual wake word: TFLM vs. X-CUBE-AI – Memory footprint
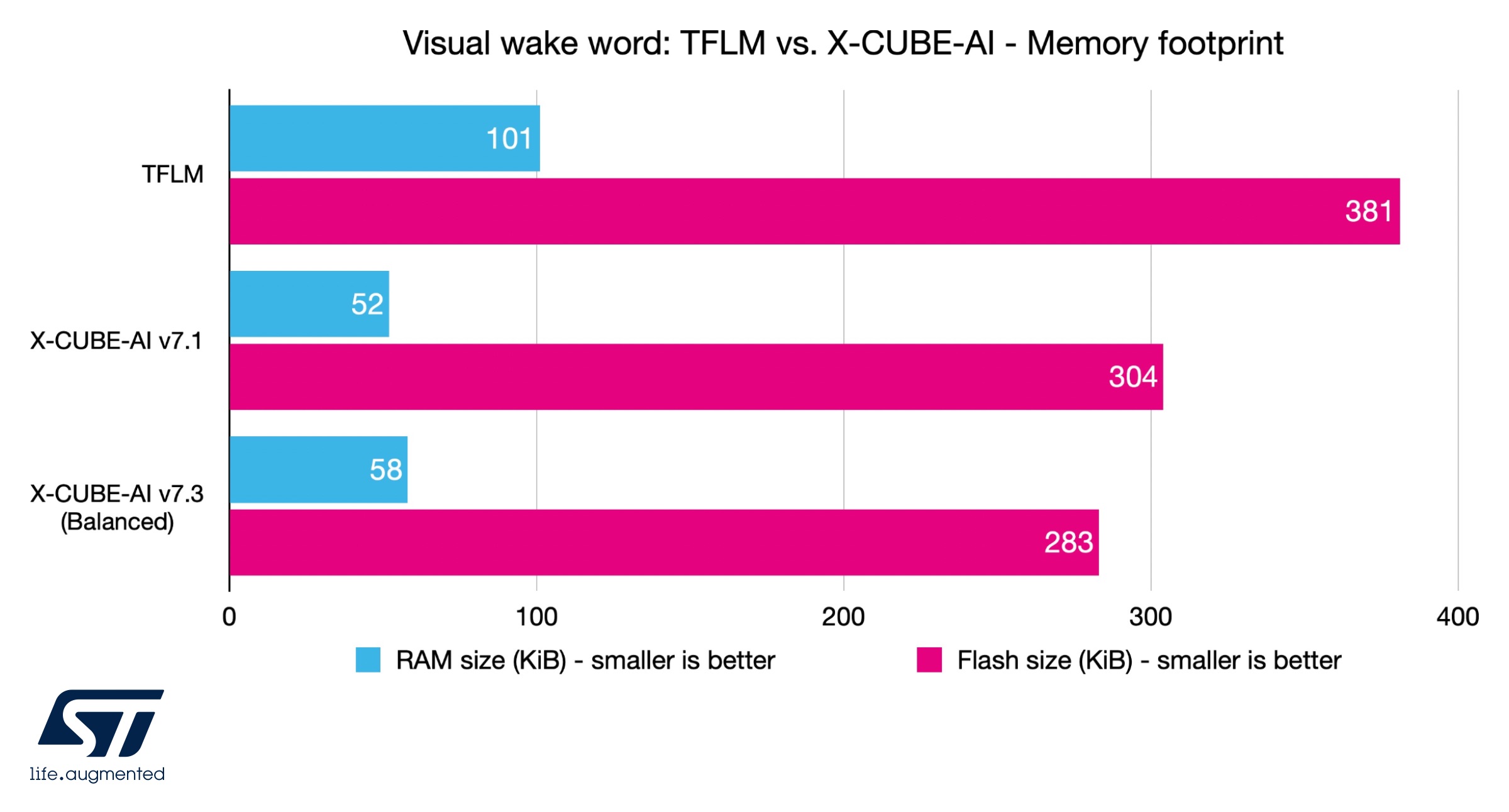
TFLM needs about almost twice as much RAM as X-CUBE-AI v7.1 and uses 25% more flash. Down the road, it would mean engineers could use far fewer memory modules and, therefore, reduce their bill of materials. Even when compared to X-CUBE-AI v7.3, TFLM needs 74% more RAM and 35% more flash, despite the ST solution being 41% faster in balanced mode due to its optimizations and support for extended layers.
More optimizations to shape the future of machine learning at ST
The impact of the STM32’s SMPS on the overall energy efficiency highlights the importance of hardware optimizations. It’s why Remi El-Ouazzane, President, Microcontrollers, and Digital ICs Group at ST, pre-announced the STM32N6 during ST’s last Capital Markets Day. The upcoming microcontroller will include a neural processing unit to improve our ecosystem’s efficiency and raw performance further. The upcoming device and today’s announcement testify to ST’s desire to surpass Tiny ML’s current limitation. Remi also divulged a new partnership around this platform, thus showing that the industry is already adopting ST’s new ecosystem. Our MLCommons membership, our optimizations in X-CUBE-AI, and our continued hardware innovations help explain why partners use our solution.
Why did MLCommons work with ST?
Fighting skewed results
In a paper last revised in 20201, and to which some ST employees contributed, scholars behind MLPerf Tiny explain the challenges that the benchmark tries to address. For instance, the document explains that hardware heterogeneity can create confusion and skew perceptions. MLPerf Tiny can, therefore, provide a leveled playing field to compare devices, whether they are general-purpose microcontrollers or dedicated neural processors. Similarly, the MLCommons test can sort out the various software running on similar devices and help engineers find the best ecosystem for them. Power consumption is also another critical consideration. Measuring the energy needed for inference operations is tricky as peripherals or firmware can hide what’s truly going on.
To better mimic real-world machine learning applications at the edge, MLCommons uses quantized models. Quantization is the process of converting tensors, the data containers in a neural network, from a floating-point precision to a fixed-point one. A quantized model is thus much smaller and uses far less memory. It also calls for integer operations that demand less computational throughput. Quantized models are, therefore, prevalent on low-power embedded systems as they vastly increase performance and power efficiency without crippling accuracy. Quantization is increasingly the norm for machine learning at the edge, as QKeras from Google recently showed. Their adoption by MLCommons was thus imperative to ensure relevancy.
Testing With 4 Use Cases
To solve the accuracy challenge, MLPerf Tiny runs through a series of four use cases: keyword spotting, visual wake words, image classification, and anomaly detection. MLCommons chose those applications as they represent the most common machine learning systems at the edge today and provide a diverse test bench. For instance, visual wake words detect if one person is in an image, such as in a doorbell system, thus measuring classic image classifications. On the other hand, the image classification use case tests new ways to perform more complex image classifications for industrial applications while keeping power consumption to a minimum.
Keyword spotting and anomaly detection will be familiar to readers of this blog. We encountered the former when we explored Alexa Voice Service on STM32s. The benchmark from MLCommons, however, looks at 1,000 speech patterns and the overall current drain. As some systems run on mobile devices, the application’s impact on the battery is critical. Anomaly detection will have similarities with what we covered when tackling condition monitoring and predictive maintenance. The dataset for this use case mirrors industrial equipment, such as side rails, fans, pumps, or valves. It is also the only use case to rely on unsupervised learning.
Segregating Closed and Open Divisions
Quantifying machine learning performance is also tricky because of how different applications can be. Ecosystems will perform very differently depending on the dataset, models, and environment. MLCommons accounts for this by running two divisions: a closed and an opened one. The closed division reflects performance in a rigid environment. Developers can’t change training or weights after the fact, and the division has a strict accuracy minimum. All tests also use the same models, dataset, and implementations. The open division, on the other hand, reflects machine learning applications that adapt over time. It’s possible to change the models, training, and datasets. Accuracy requirements are not as stringent, and submitters can show how they improved performance or power consumption over time.
STM32 MCUs and X-CUBE-AI currently provide results in the closed division only. Since the ST software converts neural networks into code optimized for STM32 MCUs but doesn’t change the neural network’s nature, running the ST ecosystem in the open division wouldn’t make sense.
How to Go From the MLCommons Benchmark to Real-World Applications?
Run a Vision Application
While benchmarks are essential, we offer demonstration applications to help developers get started on real-world products. For instance, the FP-AI-VISION1 software pack includes the source code for food recognition, person detection, and people counting. The package provides runtime neural network libraries generated by X-CUBE-AI and image processing libraries. Consequently, developers can rapidly run a machine learning demo thanks to precompiled binaries for the STM32H747I-DISCO Discovery board and the B-CAMS-OMV camera module. We also wrote a complementary Wiki that uses FP-AI-VISION1 and X-CUBE-AI to help developers create an image classification application. There’s even a tutorial on how to train a deep learning model to classify images.
Run an Industrial Sensing Application
Engineers working on industrial applications relying on sensor monitoring will want to download FP-AI-MONITOR1. This software package includes example applications featuring anomaly detection and activity classification. Users simply load binaries onto the STEVAL-STWINKT1B SensorTile wireless industrial node to run their application. This expansion pack is unique because it features software that relies on X-CUBE-AI and NanoEdge AI Studio, thus enabling developers to experiment with both solutions. NanoEdge AI Studio enables developers to run training and inference operations on the same device and choose between four algorithms.
ST wrote a Wiki to assist teams looking to run the demos found within FP-AI-MONITOR1 quickly and learn from our implementations. Additionally, the Wiki details how to use the command-line interface to configure the sensors of the development board and run classification operations.
- Learn more about MLPerf Tiny by MLCommons
- Check out X-CUBE-AI
- Download FP-AI-VISION1
- Download FP-AI-MONITOR1
- Reddi, Vijay Janapa and Cheng, Christine and Kanter, David and Mattson, Peter and Schmuelling, Guenther and Wu, Carole-Jean and Anderson, Brian and Breughe, Maximilien and Charlebois, Mark and Chou, William and Chukka, Ramesh and Coleman, Cody and Davis, Sam and Deng, Pan and Diamos, Greg and Duke, Jared and Fick, Dave and Gardner, J. Scott and Hubara, Itay and Idgunji, Sachin and Jablin, Thomas B. and Jiao, Jeff and John, Tom St. and Kanwar, Pankaj and Lee, David and Liao, Jeffery and Lokhmotov, Anton and Massa, Francisco and Meng, Peng and Micikevicius, Paulius and Osborne, Colin and Pekhimenko, Gennady and Rajan, Arun Tejusve Raghunath and Sequeira, Dilip and Sirasao, Ashish and Sun, Fei and Tang, Hanlin and Thomson, Michael and Wei, Frank and Wu, Ephrem and Xu, Lingjie and Yamada, Koichi and Yu, Bing and Yuan, George and Zhong, Aaron and Zhang, Peizhao and Zhou, Yuchen. “MLPerf Inference Benchmark”. arXiv. 2019. https://doi.org/10.48550/arxiv.1911.02549 ↩