

STM32Cube.AI v8 is highly symbolic as it supports quantized networks using the ONNX file format, while the new STM32Cube.AI Developer Cloud provides an online front-end to a model zoo and board farm to optimize workflows significantly. STM32Cube.AI continues to optimize the C code generated from a pre-trained neural network to ensure developers enjoy greater Industrial AI capabilities on MCUs. However, the new version of STM32Cube.AI and the new STM32Cube.AI Developer Cloud stand out because they focus on accessibility. Many quantized networks used ONNX, which means STM32Cube.AI now supports a wider range of training and pruning frameworks. Similarly, the new cloud services will help engineers find the right network topology and MCU faster.
From massive supercomputers to microcontrollers
What is STM32Cube.AI?
Launched in 2019, STM32Cube.AI converts neural networks into optimized code for STM32 MCUs. The fact that an algorithm can run on a resource-constraint device like a microcontroller is a critical evolution in this domain. When Arthur Samuel, the man who coined the term “machine learning”, was working on a program that would teach a computer to play checkers in 1956, he had to work on an IBM 701 mainframe and run his program on the large-scale scientific IBM 7094. Afterward, machine learning kept requiring massive computational throughput. Even a couple of years before ST launched STM32Cube.AI, industry leaders all ran machine learning algorithms on clouds made of powerful machines.
STM32Cube.AI is special because it helps run algorithms on MCUs and makes developing a machine-learning application easier. It relies on STM32CubeMX, which assists developers in initializing STM32 devices, and X-CUBE-AI, a software package containing libraries to convert pre-trained neural networks. The solution, therefore, uses a familiar and accessible development environment. Teams can even use our Getting Started Guide to start working with X-CUBE-AI from within STM32CubeMX and try the latest features rapidly. As a result, more applications rely on our technology. For instance, the added support for deeply quantized neural networks introduced in an earlier version quickly found its way into a people-counting application created with Schneider Electric.
What’s new?
STM32Cube.AI Developer Cloud
Board Farm

The new Cloud Services features a board farm with most of the STM32 development boards used for machine learning applications. STM32Cube.AI Cloud Services can take a pre-trained neural network and launch a simulation on the entire board farm to show how a model would behave on each system.
Consequently, developers don’t have to acquire all the boards and run a long series of benchmarks. They can immediately gauge inference times to determine which platform would have the best performance-per-cost ratio for their use case. The tool only shows inference times as the Desktop version of STM32Cube.AI provides additional information like power consumption or memory footprint. Moreover, to make the STM32Cube.AI Developer Cloud even more practical, we developed a series of REST APIs so engineers can test their network against our board farm by using a simple script for greater productivity.
Model Zoo
Another feature of the STM32Cube.AI Developer Cloud is the ST Model Zoo. As Industrial AI gets increasingly popular, more engineers make their first step into machine learning. Still, some may have difficulty knowing where to start and, more specifically, what neural network model to adopt. The ST Model Zoo solves that problem by recommending a series of models for various applications and use cases (image classification, object detection, human activity recognition, and audio event detection). Hence, engineers who know how to train a network and already have a dataset can get a series of network topologies recommendations to avoid issues like memory limits or poor performance.
STM32Cube.AI Cloud Services uses the same my.st.com logins, so users with an existing account can already access the service. It is also possible to use the Model Zoo in collaboration with the Board Farm to determine the impact of various topologies and further test different approaches during the prototyping phase. As a result, developers can better anticipate their needs, tailor their solutions, and reduce the time it takes to launch an optimal machine-learning solution. The STM32Cube.AI Developer Cloud is thus a unique way to make Industrial AI more practical and accessible to the embedded system community.
What’s in STM32Cube.AI?
Optimization Mode
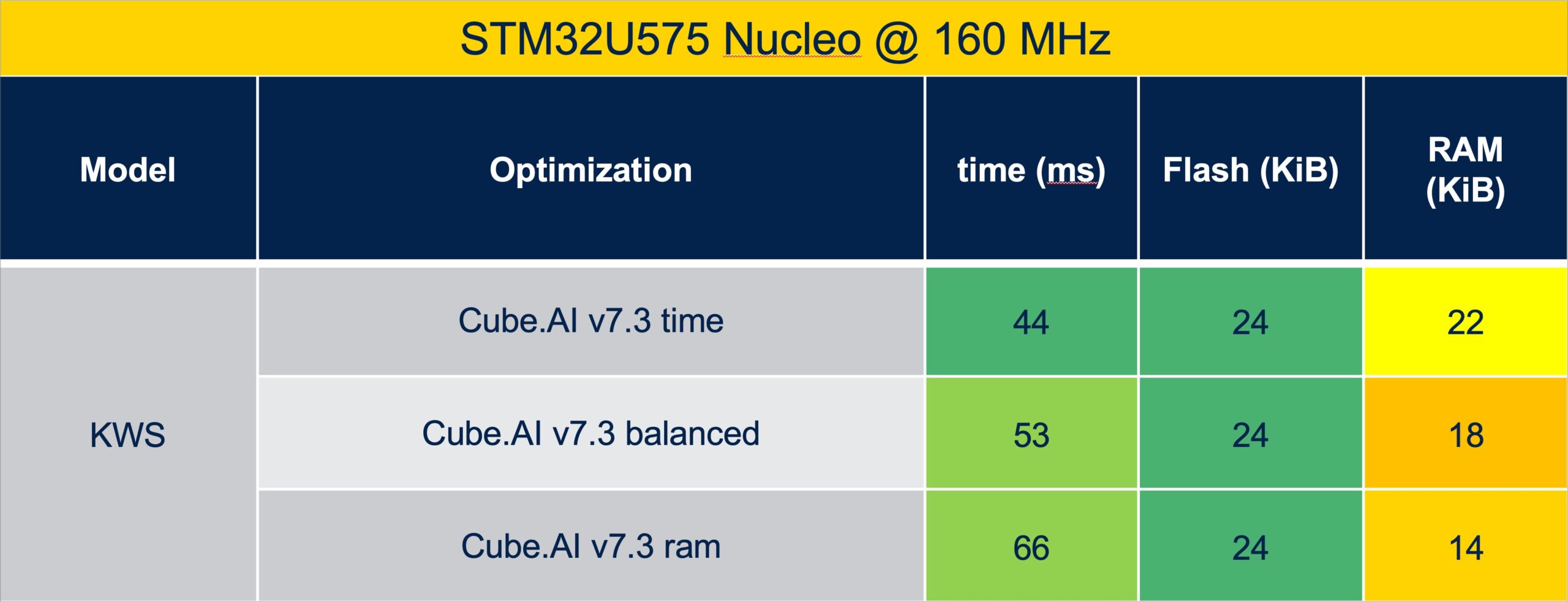
STM32Cube.AI v7.3 brings a new feature that allows developers to prioritize RAM or inference times. Thanks to the introduction of extended layers in the previous version, the ST solution optimized performance. However, it also meant that the algorithm could have a larger footprint in the volatile memory. To give developers more control over their applications, ST introduced a new setting in STM32Cube.AI v7.3 to define priorities. If users choose the “Time” setting, the algorithm will take more RAM but have faster inference times. On the other hand, choosing “RAM” will have the smallest memory footprint and the slowest times. Finally, the default “Balanced” parameter finds the middle ground between the two approaches, providing a good compromise.
According to our benchmarks, in some cases, reducing the RAM footprint by 36% increases inference times by 50%. If we look at the ratio, 2 KiB of RAM equals 1 ms of inference time when using the “Time” setting, but the ratio significantly worsens when choosing “RAM”. Hence, in many instances, users will choose “Time” and enjoy the greater performance-per-memory ratio. However, we know that some customers are extremely constrained by RAM and count every kilobyte. In this instance, engineers will gladly take the lower inference times to save memory, which is why we worked to offer a granular experience that helps developers tailor applications to their needs, thus further popularizing machine learning at the edge.
STM32Cube.AI: From Research to Real-World Software
What Is a Neural Network?

STM32Cube.AI takes a pre-trained neural network and converts it into optimized code for STM32 MCUs. In its simplest form, a neural network is simply a series of layers. There’s an input layer, an output layer, and one or more hidden layers in between the two. Hence, deep learning refers to a neural network with more than three layers, the word “deep” pointing to multiple intermediate layers. Each layer contains nodes, and each node is interconnected with one or more nodes in the lower layer. Hence, in a nutshell, information enters the neural by the input layer, travels through the hidden layers, and comes out of one of the output nodes.
What Are a Quantized Neural Network and a Binarized Neural Network?
To determine how information travels through the network, developers use weights and biases, parameters inside a node that will influence the data as it moves through the network. Weights are coefficients. The more intricate the weight, the more accurate a network but the more computationally intensive it becomes. Each node also uses an activation function to determine how to transform the input value. Hence, to improve performance, developers can use quantized neural networks, which use lower precision weights. The most efficient quantized neural network would be a binarized neural network (BNN), which only uses two values as weight and activation: +1 and -1. As a result, a BNN demands very little memory footprint but is also the least accurate.
Why Deeply Quantized Neural Networks Matter?
The industry’s challenge was to find a way to simplify neural networks to run inference operations on microcontrollers without sacrificing accuracy to the point of making the network useless. To solve this, researchers from ST and the University of Salerno in Italy worked on deeply quantized neural networks. DQNNs only use small weights (from 1 bit to 8 bits) and can contain hybrid structures with only some binarized layers while others use a higher bit-width floating-point quantizer. The research paper1 by ST and the university researchers showed which hybrid structure could offer the best result while achieving the lowest RAM and ROM footprint.
The new version of STM32Cube.AI is a direct result of those research efforts. Indeed, version 7.2 supports deeply quantized neural networks to benefit from the efficiency of binarized layers without destroying accuracy. Developers can use frameworks from QKeras or Larq, among others, to pre-train their network before processing it through X-CUBE-AI. Moving to a DQNN will help save memory usage, thus enabling engineers to choose more cost-effective devices or use one microcontroller for the entire system instead of multiple components. STM32Cube.AI thus continues to bring more powerful inference capabilities to edge computing platforms.
From a Demo Application to Market Trends
How Makes a People Counting Demo?
ST and Schneider Electric collaborated on a recent people counting application that took advantage of a DQNN. The system ran inference on an STM32H7 by processing thermal sensor images to determine if people crossed an imaginary line and in which direction to decide if they were entering or leaving. The choice of components is remarkable because it promoted a relatively low bill of material. Instead of moving to a more expensive processor, Schneider used a deeply quantized neural network to significantly reduce its memory and CPU usage, thus shrinking the application’s footprint and opening the door to a more cost-effective solution. Both companies showcased the demo during the TinyML conference last March 2022.
How to Overcome the Hype of Machine Learning at the Edge?
ST was the first MCU manufacturer to provide a solution like STM32Cube.AI, and our tool’s performance continues to rank high, according to MLCommons benchmarks. As this latest journey from an academic paper to a software release shows, the reason behind our performance is that we prioritize meaningful research that impacts real-world applications. It’s about making AI practical and accessible instead of a buzzword. Market analysts from Gartner2 anticipate that companies working on Embedded AI will soon be going through a “trough of disillusionment.” The demo application with Schneider shows that by being first and driven by research, ST overcame this slope by being at the center of practical applications and thoughtful optimizations.
ST also recently joined the MLCommons™ consortium. The initiative enables us to contribute to the community and will help teams figure out what they can do with machine learning at the edge, thanks to objective and repeatable benchmarks.
- D. Pau, M. Lattuada, F. Loro, A. De Vita and G. Domenico Licciardo. “Comparing Industry Frameworks with Deeply Quantized Neural Networks on Microcontrollers”. 2021. IEEE International Conference on Consumer Electronics (ICCE)pp. 1-6, https://doi.org/10.1109/ICCE50685.2021.9427638. ↩︎
- “5 Trends Drive the Gartner Hype Cycle for Emerging Technologies, 2020.” www.gartner.com. ↩︎