

ST held a lecture on how it uses Convolutional Neural Networks (CNN or ConvNets) at Embedded World 2018 to show how Deep Learning will impact future embedded systems. The talk and research itself are fascinating because mainstream, or even technical media, don’t often associate Deep Learning with low-power embedded systems. Very often, discussions only evolve around Machine Learning, a computer science discipline focusing on algorithms that use data to learn patterns or models to inform future decisions. For instance, a system determines what music a user likes and makes recommendations. Deep Learning is a subset of Machine Learning that shares those guiding principles but parses a tremendous amount of data and uses neural networks to learn and make decisions.
As their name implies, neural networks are interconnections of small processing and storage centers that try to mimic biological neurons. There are many types of neural networks, but in the lecture, ST focuses on Convolutional Neural Networks, which use multiple layers, each one with a specific function. They are now a lot more popular than competing solutions and are highly efficient at image or video recognition. And since ST is always looking to better sense the world around us, it was only natural for our teams to explore this emerging field. Hence, to better understand the ST research around it and help share it with our readers who couldn’t attend Embedded World 2018, we sat down with Dr. Giuseppe Desoli, a Fellow member of the ST technical staff, Research and Development Director, and the lead author of the paper presented during the conference.
What Is Orlando?
Dr. Desoli, who was also a guest speaker at the last ASTDay, explained in his paper entitled A New Scalable Architecture to Accelerate Deep Convolutional Neural Networks for Low Power IoT Applications that the seminal work of Yann LeCun was a starting point for his research. It clearly showed that CNNs can significantly outperform classical computers in image recognition operations. From this moment on, ST started researching this field, and at ISSCC (International Solid-State Circuits Conference) 2017 revealed Orlando, an ultra-low power System-on-Chip (SoC) capable of accelerating Deep Convolutional Neural Networks algorithms. Embedded World 2018 was thus an excellent opportunity for ST and Dr. Desoli to share more details on the chip’s architecture and its performance.
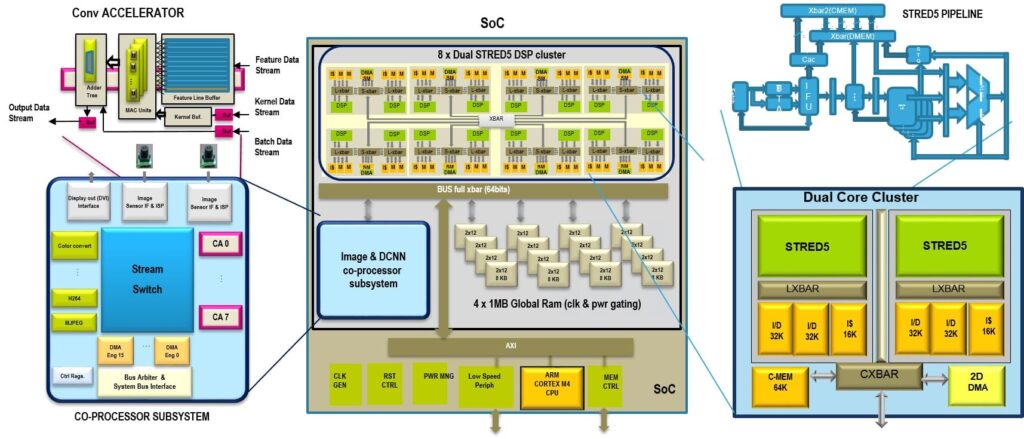
Orlando uses a Cortex-M4 microcontroller (MCU) and 128 KB of memory, eight programmable clusters each containing two 32-bit DSPs, and four SRAM banks, each bank offering four modules of 2 x 64 KB each. Coupled with this highly efficient core is an image and CNN co-processor (called the Neural Processing Unit or NPU) that integrates eight Convolutional Accelerators (CA), among other things. In large networks, engineers can use multiple SoCs and connect them using a 6 Gbps four-lane link.
The 6.2 mm x 5.5 mm die uses a 28 nm Fully Depleted Silicon On Insulator (FD-SOI) process node, which provides significant advantages when it comes to ultra-low power designs. In the lab, it can run at up 1.175 GHz with an applied voltage of 1.1 V, reaching up to 676 GOPS (Giga Operations Per Second) with 8 CAs. However, running at an average of 200 MHz at 0.575 V, Orlando’s power consumption rises to only 41 mA on AlexNet at 10 frames per second (FPS).
What Makes Orlando Special?
The ultra-low-power of Orlando is probably one of its most surprising specifications, but as Dr. Desoli explained to us:
“As long as you can reach a certain performance threshold, the primary objectives to a pertinent prototype are cost and power consumption, and Orlando’s specifications are only possible because ST has a very special grip on the technology. We are very invested in IoT and all our sensing capabilities continue to make up the nervous systems of the connected world. Augmenting the perception functionalities at the periphery of this environment is therefore the next logical step of our innovations as we continue to offer more features to our clients.”

As a result, Orlando is much more than a simple demo chip to show at conferences, but a framework for hardware accelerators that could soon shape future IoT applications. Indeed, the prototype serves as a template to validate architectures that could potentially see an eventual commercial application. One of its main advantages is its flexibility as it’s possible to use more or fewer hardware blocks to offer varying degrees of computational throughput to fit the needs of an application or a product. Hence, it’s possible to scale the architecture from a simple accelerator that sits at the edge of an IoT network to something with much more computational throughput for an intermediary node or gateway.
What Makes ST’s Research Special?
As a result, Dr. Desoli also talked about benchmarks and numbers to show how far ST has come since the ISSCC presentation in 2017. For instance, when Orlando runs at 200 MHz and consumes only 41 mW, the system can reach a peak of 2.9 TOPS/W on AlexNet when using eight CAs. However, the average performance isn’t too far off at 2.4 TOPS/W for the whole network when using 8-bit coefficients. Switching to 16-bit coefficients drops the throughput to 2 TOPS/W. Additionally, we are finalizing a new version of the accelerators’ framework which pushes the efficiency beyond 10 TOPS/W.
For instance, in VGG–16, one of the most compute-intensive CNN topologies, a CA running at 200 MHz has an efficiency of 130 FPS/W (Frames Per Second Per Watt) while a 16-CA configuration boosts it at 440 FPS/W thanks to the streaming architecture that optimizes memory bandwidth and power savings These tests assign 512 KB of internal on-chip memory to the CNN workload, which is very close to the specification of a real-world product.
Indeed, these benchmarks don’t try to show unrealistic performance peaks but aim to prove that under average load, Orlando already achieves exciting results, which is one of the greatest strengths of this paper. There are research materials with much more hyperbolic numbers, but by producing a SoC, and by using a Cortex core as well as a realistic architecture, ST is demonstrating that Neural Networks in embedded systems aren’t limited to laboratories or 10-year roadmaps. In just one year, we’ve shown that we could go from a demonstration to a realistic prototype with many commercial applications. Hence, the last thing we can stay is: stay tuned, because this isn’t the last time we’ll talk about Orlando!